Real-time speech recognition with Python
Learn how to do real time streaming speech-to-text conversion in Python using the AssemblyAI Universal-Streaming speech-to-text API.



Overview
Real-time speech recognition in Python is powered by the AssemblyAI Python SDK. The SDK provides a StreamingClient that handles the complexities of WebSocket connections and a MicrophoneStream helper for easy audio capture. This feature, available on our free tier, processes audio as you speak.
We'll install PyAudio and websockets, then build an async application that streams microphone audio to AssemblyAI's websocket endpoint.
Prerequisites
Before we start writing code, you'll need a few things:
Install the libraries using pip:
pip install assemblyai
Our SDK's microphone streaming utility requires the pyaudio library. If you don't have it, install it as well:
pip install pyaudio
If PyAudio installation fails, install the PortAudio dependency first:
Basic speech-to-text with Python
The simplest way to get started is by transcribing a local audio file. This confirms your environment and API key are set up correctly before we move to real-time streaming. While this article focuses on real-time, understanding the basic file upload method is a great first step.
You can use our API to transcribe a file by sending a POST request with the audio file's location. The API then returns a transcript object. This approach is ideal for pre-recorded audio, like interviews or podcasts.
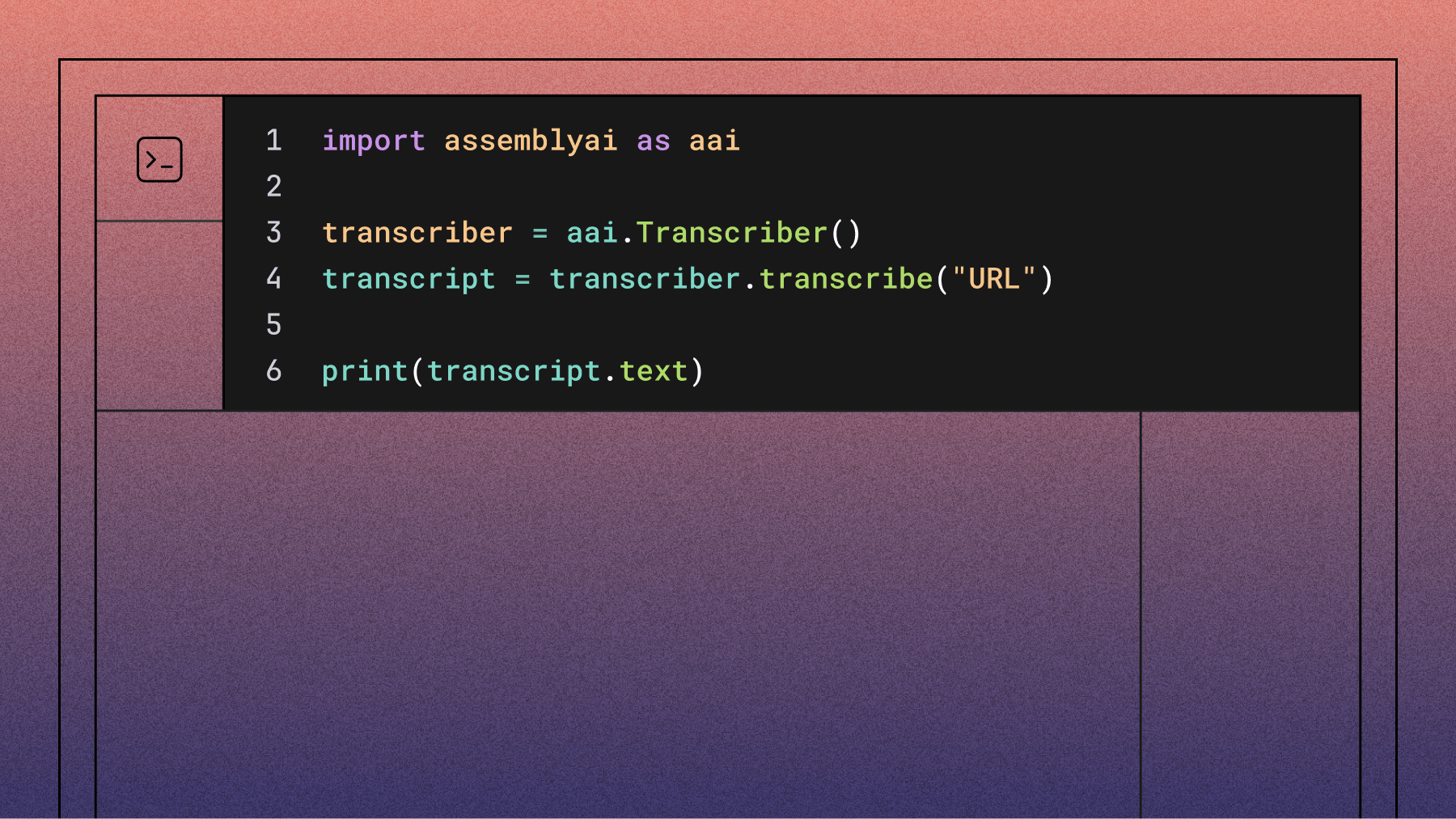
import assemblyai as aai
aai.settings.api_key = "YOUR_API_KEY"
transcriber = aai.Transcriber()
transcript = transcriber.transcribe("./my-local-audio-file.mp3")
print(transcript.text)
Real-time speech recognition setup
Now that you've seen how basic transcription works, let's build the real-time application. The AssemblyAI Python SDK provides a StreamingClient that makes it simple to transcribe live audio from a microphone. This is perfect for applications that need immediate voice input, like voice commands or live captioning.
The process involves four main steps:
Connect to AssemblyAI's Streaming API
We'll use the StreamingClient to connect to AssemblyAI's real-time transcription service. The client works with event handlers, which are functions that you define to process events like the connection opening, receiving a transcript, or encountering an error.
First, let's define our event handlers and set up the client in a main function:
import logging
from typing import Type
import assemblyai as aai
from assemblyai.streaming.v3 import (
BeginEvent,
StreamingClient,
StreamingClientOptions,
StreamingError,
StreamingEvents,
StreamingParameters,
TerminationEvent,
TurnEvent,
)
# Configure your API key
API_KEY = "YOUR_API_KEY"
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Define event handlers
def on_begin(self: Type[StreamingClient], event: BeginEvent):
print(f"Session started: {event.id}")
def on_turn(self: Type[StreamingClient], event: TurnEvent):
print(f"{event.transcript} ({event.end_of_turn})")
def on_terminated(self: Type[StreamingClient], event: TerminationEvent):
print(f"Session terminated: {event.audio_duration_seconds} seconds of audio processed")
def on_error(self: Type[StreamingClient], error: StreamingError):
print(f"Error occurred: {error}")
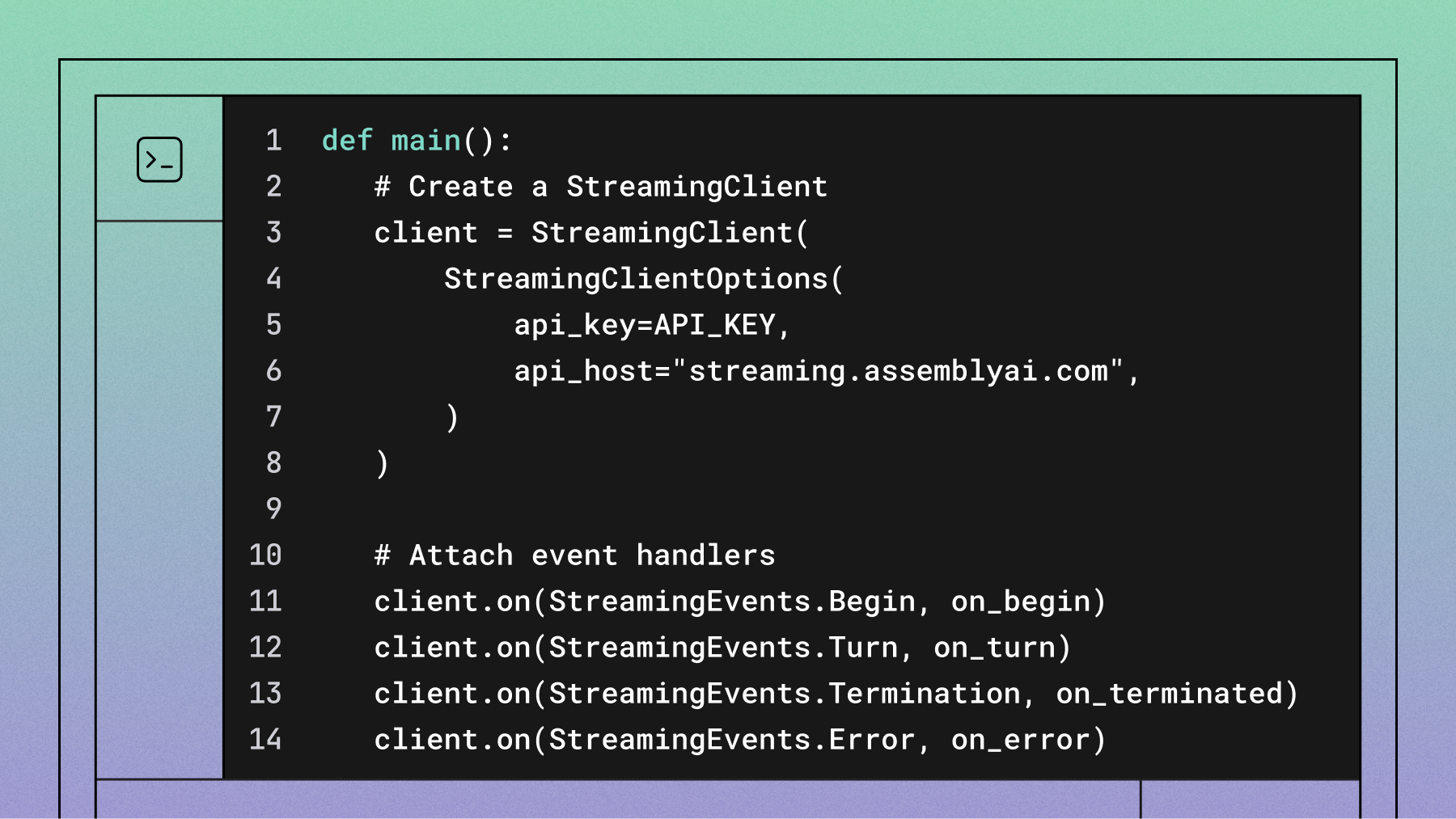
def main():
# Create a StreamingClient
client = StreamingClient(
StreamingClientOptions(
api_key=API_KEY,
api_host="streaming.assemblyai.com",
)
)
# Attach event handlers
client.on(StreamingEvents.Begin, on_begin)
client.on(StreamingEvents.Turn, on_turn)
client.on(StreamingEvents.Termination, on_terminated)
client.on(StreamingEvents.Error, on_error)
# Connect to the streaming service
client.connect(
StreamingParameters(
sample_rate=16000,
format_turns=True,
)
)
print("Listening to microphone... Press Ctrl+C to stop.")
# Stream audio from the microphone
try:
client.stream(
aai.extras.MicrophoneStream(sample_rate=16000)
)
finally:
# Ensure the client disconnects gracefully
client.disconnect(terminate=True)
if __name__ == "__main__":
main()
This single script handles everything: setting up the client, defining how to react to different events (like receiving a transcript turn), connecting, and streaming audio. The SDK's aai.extras.MicrophoneStream utility handles capturing audio, so we don't need to manage PyAudio manually.
Handle errors and connection issues
In a production application, network connections can be unreliable. The SDK's StreamingClient simplifies error handling. By attaching a function to the StreamingEvents.Error event, you can gracefully manage unexpected issues without complex try...except blocks for WebSocket exceptions.
In our example, the on_error function will be called automatically if the connection drops or another session error occurs, printing the error to the console. For a production system, you could implement logic here to log the error to a monitoring service or attempt to reconnect.
Run your real-time speech recognition
With the complete script ready, you can run it from your terminal:
python your_script_name.py
Start speaking, and you'll see the transcribed text printed to your console in real time. The on_turn event handler processes each segment of speech as it's finalized. When you're finished, press Ctrl+C to stop. The try...finally block ensures that client.disconnect() is called, gracefully closing the session.
Optimize performance and accuracy
The default settings are a good starting point, but you can tune parameters for your specific use case. The sample_rate and turn detection parameters are key.
Here's a breakdown of the main turn detection parameters:
ParameterDescriptionDefaultUse Caseend_of_turn_confidence_thresholdControls how confident the model must be to trigger an end-of-turn based on semantic cues. Lower values are more aggressive.0.7Lower for quick commands; higher for thoughtful speech.min_end_of_turn_silence_when_confidentThe silence (in ms) required after speech before a high-confidence end-of-turn is triggered.160Lower for faster responses, higher to allow for brief pauses.max_turn_silenceThe maximum silence (in ms) allowed before an end-of-turn is forced, even with low confidence.2400The final backstop to detect the end of a turn.
Experiment with these values in the StreamingParameters object to find the right balance between responsiveness and allowing users to pause naturally.
Next steps with Speech AI
Your real-time speech recognition application is ready for production. Extend it with additional Speech AI capabilities:
Check the API documentation for implementation details. Try our API for free to get started.
Frequently asked questions about speech-to-text in Python
How do I fix PyAudio installation issues on different operating systems?
Install PortAudio first: brew install portaudio (macOS), sudo apt-get install libasound-dev portaudio19-dev (Linux), or download a pre-compiled wheel for Windows. This resolves most PyAudio installation issues.
What sample rate and audio format should I use for best accuracy?
Use 16,000 Hz sample rate with 16-bit format (pyaudio.paInt16) for optimal accuracy and performance. Higher rates increase bandwidth without improving transcription quality.
How do I handle websocket disconnections and network errors?
The AssemblyAI Python SDK simplifies error handling. By defining an on_error event handler and attaching it to your StreamingClient, you can centralize your error logic. The SDK manages the underlying WebSocket connection state, so you don't need to manually catch specific connection errors or implement reconnection logic.
Why is my real-time transcription slow or inaccurate?
For latency, you can tune the turn detection parameters like end_of_turn_confidence_threshold to get faster responses. For accuracy, ensure you are providing a clean audio stream at a 16kHz sample rate. Poor audio quality, incorrect sample rates, or network issues are the most common causes of slow or inaccurate transcription.
Can I use AssemblyAI for offline speech recognition?
AssemblyAI requires an internet connection and doesn't offer offline solutions. You can transcribe local files via file upload, which doesn't need persistent streaming connections.
/
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts