Speech-to-text AI: A complete guide to modern speech recognition technology
Read our complete guide to modern speech recognition technology.



Speech-to-text AI now powers critical applications across industries—from medical dictation software processing complex terminology to real-time meeting transcription capturing nuanced business discussions. When Siri launched in 2011, its occasional misunderstandings became running jokes. Today's speech recognition systems power critical applications across different accents and environments.
The transformation isn't just about better technology. It's about speech-to-text AI becoming reliable enough to handle mission-critical tasks. Companies now build entire products around voice interaction, confident that the underlying recognition will work consistently.
What is speech-to-text AI?
Speech-to-text AI converts spoken language into written text using artificial intelligence models. Unlike traditional rule-based systems that relied on phonetic dictionaries and limited vocabularies, modern speech-to-text AI uses neural networks to understand the complex patterns in human speech.
These systems analyze audio signals, identifying words, phrases, and contextual patterns with high accuracy. For real-time applications, modern systems can process speech as it's spoken with sub-second latencies. The AI component means the system learns and improves from vast amounts of voice data, handling variations in pronunciation, background noise, and speaking styles that would challenge traditional approaches.
How speech-to-text AI works
Modern speech-to-text AI systems operate through several sophisticated processes working in concert:
Audio preprocessing cleans and prepares the incoming audio signal. The system removes background noise, normalizes volume levels, and segments the audio into analyzable chunks. This preprocessing stage is crucial—clean input data dramatically improves recognition accuracy.
Neural network processing forms the core of modern systems. Deep learning models, often based on transformer architectures, analyze the audio patterns and convert them into text predictions. These networks have been trained on millions of hours of speech data, learning to recognize patterns across different accents, languages, and speaking conditions.
Language modeling ensures the output makes linguistic sense. Even if the audio is unclear, the language model uses context to predict the most likely words based on what came before. This is why modern systems rarely produce nonsensical phrases like older recognition software.
Post-processing adds punctuation, capitalizes proper nouns, and formats the final output. Advanced systems can identify sentence boundaries, add paragraph breaks, and even detect emotional tone in the speech.
The entire process happens in milliseconds for real-time applications, or can be optimized for higher accuracy when processing recorded audio asynchronously.
Types of speech-to-text AI systems
Understanding the different approaches helps when selecting the right solution for your specific needs.
Cloud-based speech recognition
Cloud-based systems process audio on remote servers, offering several advantages. They can leverage massive computational resources and are continuously updated with the latest models. Services like AssemblyAI's Speech AI models exemplify this approach, providing industry-leading accuracy through constantly improving neural networks.
The trade-off is latency and internet dependency. Audio must travel to the cloud for processing, which adds some delay. For applications requiring immediate responses, this might be a consideration.
On-device speech recognition
On-device processing keeps audio local, eliminating latency and privacy concerns. Apple's Siri and Google's offline voice typing use this approach for basic commands and short phrases.
However, on-device models are constrained by hardware limitations. They typically offer lower accuracy than cloud-based systems, especially for complex terminology or challenging audio conditions.
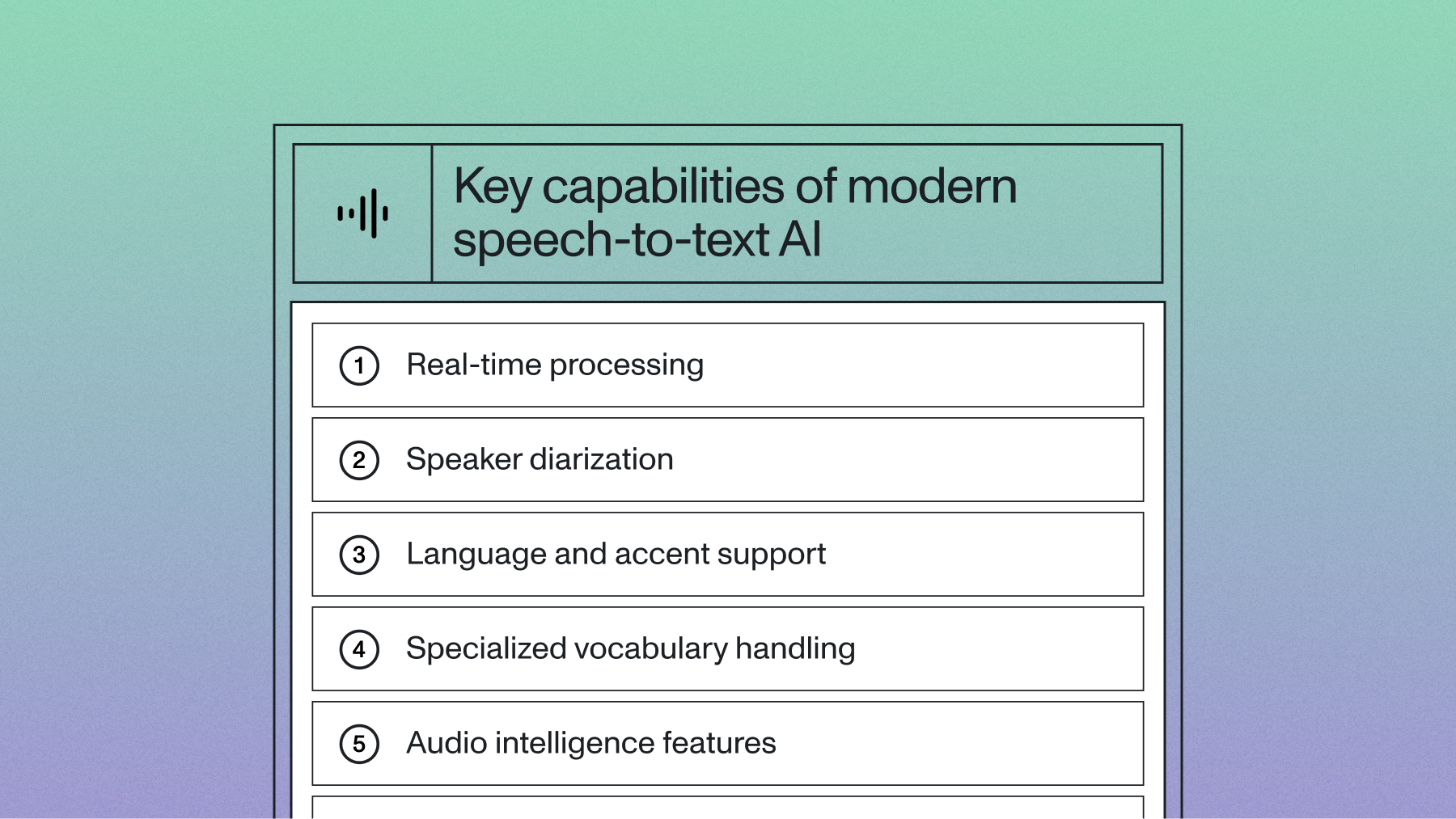
Key capabilities of modern speech-to-text AI
Today's speech recognition systems offer capabilities that extend far beyond basic transcription.
Real-time processing
Live transcription has become remarkably sophisticated. Modern systems can process speech as it's spoken, providing immediate feedback for applications like live captioning, voice assistants, and meeting notes. AssemblyAI's Universal-Streaming API, for instance, achieves immutable transcripts in ~300ms, enabling natural conversation flow for voice agents.
Speaker diarization
Advanced systems can identify and separate multiple speakers in a conversation. This capability proves essential for meeting transcription, podcast processing, and any application involving group discussions. The AI analyzes voice patterns, pitch, and speaking characteristics to distinguish between different speakers.
Language and accent support
Modern speech-to-text AI systems handle dozens of languages and can adapt to various accents within each language. This global capability opens applications to worldwide audiences without requiring separate recognition systems.
Specialized vocabulary handling
Professional applications often require recognition of technical terms, brand names, or industry-specific jargon. Advanced systems allow vocabulary customization, boosting accuracy for specialized terminology that might not appear in general training data.
For applications requiring domain-specific accuracy, newer speech language models like AssemblyAI's Slam-1 enable customization through prompting rather than model retraining. These models adapt to specialized terminology in legal, medical, or technical contexts through keyword prompting.
Speech understanding features
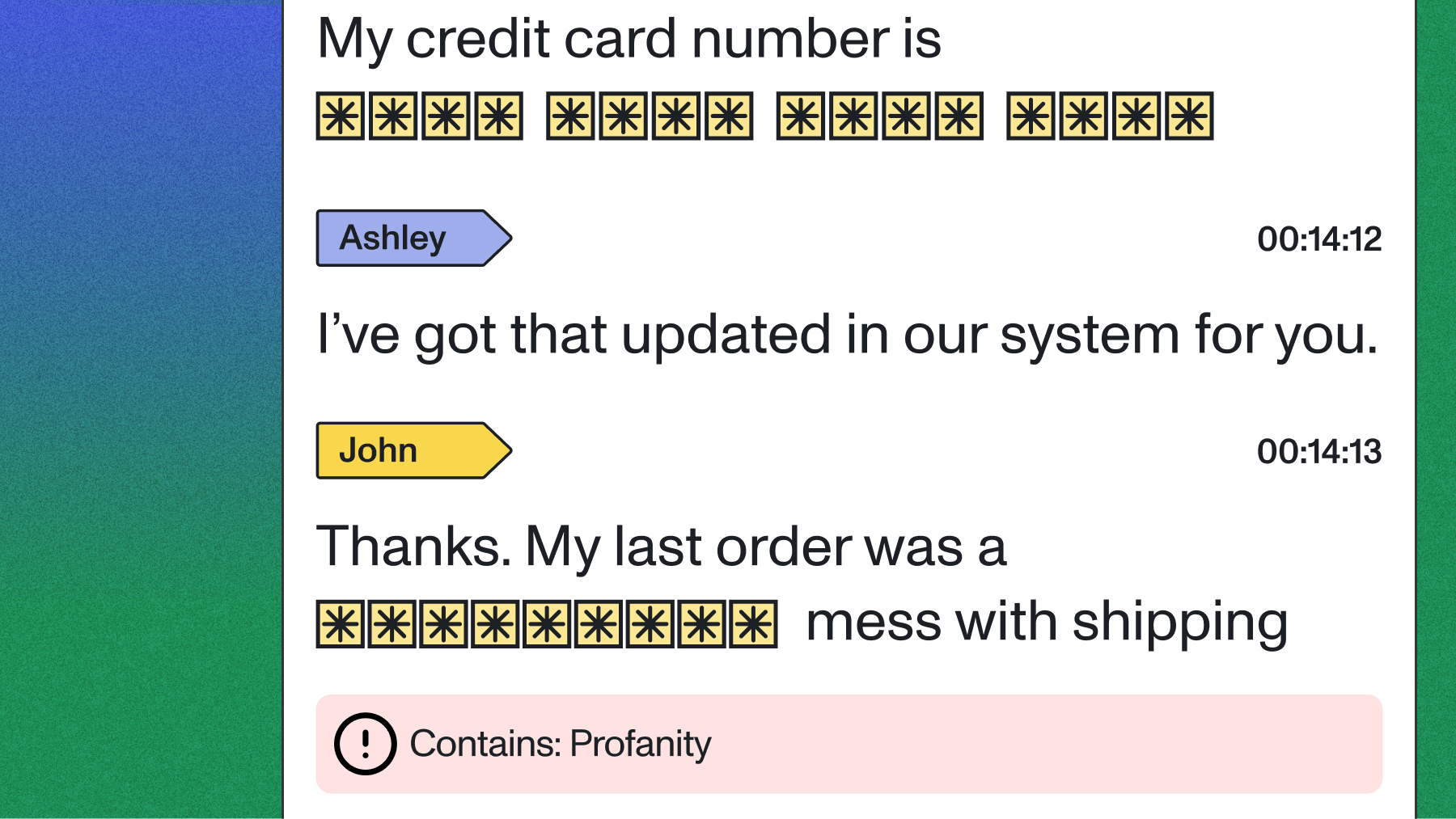
Beyond basic transcription, modern systems can analyze sentiment, detect key phrases, identify topics, and even flag sensitive information like personally identifiable information (PII) for automatic redaction.
Applications across industries
Speech-to-text AI has found applications across virtually every industry, each with unique requirements and challenges.
Healthcare and medical documentation
Medical professionals use speech recognition for patient records, prescription dictation, and clinical note-taking. The technology needs to handle complex medical terminology while maintaining HIPAA compliance with SOC 2 Type 2 certification, HIPAA BAA availability, and GDPR compliance. Accuracy is paramount—a misrecognized drug name or dosage could have serious consequences.
Medical speech-to-text systems achieve accuracy rates above 95% for trained speakers. Specialized models understand medical terminology through contextual prompting, reducing documentation time for healthcare professionals.
Customer service and contact centers
Contact centers process millions of customer interactions daily. Speech-to-text AI enables automatic call transcription for quality monitoring, sentiment analysis for identifying frustrated customers, and real-time agent coaching based on conversation analysis.
The technology helps identify trends across customer calls, automatically categorize issues, and ensure compliance with regulatory requirements by transcribing all interactions with proper SOC 2 Type 2 certification and GDPR compliance.
Media and content creation
Podcasters, video creators, and journalists use speech-to-text AI to generate transcripts, create searchable content archives, and produce closed captions. The technology has made content more accessible while reducing manual transcription costs.
Broadcast media uses real-time speech recognition for live captioning, ensuring accessibility for hearing-impaired audiences during news broadcasts and live events.
Legal and compliance
Law firms and legal departments transcribe depositions, court proceedings, and client meetings. Legal transcription demands extremely high accuracy—misrecognized legal terms or case names can impact case outcomes.
The technology also supports compliance monitoring in regulated industries, automatically transcribing and analyzing communications for regulatory violations or concerning language with proper security certifications including SOC 2 Type 2 and GDPR compliance.
Education and accessibility
Educational institutions use speech-to-text AI for lecture transcription, student note-taking assistance, and accessibility support. Students with hearing impairments benefit from real-time captioning, while language learners can see written versions of spoken content.
The technology also supports language learning applications, helping students practice pronunciation by comparing their speech to target pronunciation patterns.
Choosing the right speech-to-text AI solution
Selecting an appropriate speech-to-text AI system requires evaluating multiple factors based on your specific requirements.
Accuracy requirements and measurement
Word Error Rate (WER) serves as the standard accuracy metric, but real-world performance depends on your specific use case. A 5% WER might be acceptable for casual note-taking but inadequate for medical transcription.
Consider accuracy across different conditions:
- Clean audio: How well does the system perform with high-quality recordings?
- Noisy environments: Can it handle background conversations, traffic, or other interference?
- Accented speech: Does it maintain accuracy across different regional accents and speaking patterns?
- Technical terminology: How does it perform with industry-specific vocabulary?
Latency and processing speed
Response time requirements vary dramatically by application. Voice assistants need near-instantaneous responses, while podcast transcription can tolerate longer processing times in exchange for higher accuracy.
Real-time applications require streaming recognition with sub-second latencies. Consider whether you need immediate partial results or can wait for complete utterances.
Batch processing applications can optimize for accuracy over speed, using more computationally intensive models that produce higher-quality results.
Privacy and security considerations
Audio data often contains sensitive information, making privacy and security paramount considerations.
On-premise solutions keep all data within your infrastructure but require significant technical resources and may offer lower accuracy than cloud-based alternatives.
Cloud solutions with strong privacy practices delete audio data after processing and encrypt data in transit and at rest. Look for providers with SOC 2 Type 2 certification, HIPAA BAA availability, and GDPR compliance with clear data handling policies.
Hybrid approaches can process sensitive audio on-premises while using cloud services for non-sensitive content, balancing security with performance.
Integration and development requirements
Consider your technical team's capabilities and timeline constraints:
API-first solutions like AssemblyAI provide comprehensive documentation, code samples, and support, enabling rapid integration without extensive AI expertise.
SDK availability for your preferred programming languages reduces development time and maintenance overhead.
Webhook support enables real-time notifications when transcription completes, essential for workflow automation.
Custom vocabulary and model fine-tuning capabilities allow optimization for your specific use case and terminology.
Scalability and cost considerations
Understanding pricing models and scalability characteristics prevents surprises as your application grows.
Usage-based pricing charges per minute of audio processed, making it predictable for applications with known volume patterns.
Subscription models sometimes offer better economics for high-volume applications with consistent usage.
Rate limiting and throttling policies affect how quickly you can process large volumes of audio during peak periods.
Consider both current needs and projected growth. A solution that works for thousands of hours monthly might not scale to millions without architectural changes.
Implementation best practices
Successful speech-to-text AI implementations require attention to both technical and user experience considerations.
Audio quality optimization
High-quality input dramatically improves recognition accuracy:
Microphone selection affects input quality. Directional microphones reduce background noise pickup, while good frequency response ensures clear voice capture.
Recording environment matters significantly. Minimize echo, background noise, and multiple simultaneous speakers when possible.
Audio preprocessing can improve results. Noise reduction algorithms, automatic gain control, and echo cancellation enhance recognition accuracy.
Error handling and user experience
Even the best speech-to-text AI systems make mistakes. Design your application to handle errors gracefully:
Confidence scores help identify uncertain transcriptions that might need human review or confirmation.
Correction interfaces allow users to quickly fix recognition errors, improving their experience and potentially providing feedback for system improvement.
Fallback mechanisms ensure your application remains functional even when speech recognition fails completely.
Performance monitoring and optimization
Implement monitoring to understand real-world performance:
Accuracy tracking across different user groups, audio conditions, and content types helps identify improvement opportunities.
Latency monitoring ensures response times meet user expectations, especially for real-time applications.
Error analysis reveals patterns in recognition failures, guiding optimization efforts and user education.
Future trends in speech-to-text AI
The field continues evolving rapidly, with several trends shaping the future landscape.
Multimodal AI integration
Future systems will combine speech recognition with visual cues, understanding context from facial expressions, gestures, and environmental information. This multimodal approach could dramatically improve accuracy and enable new application categories.
Edge computing advancement
Improving hardware capabilities make sophisticated on-device speech recognition increasingly viable. Apple's Neural Engine and Google's Tensor chips demonstrate the trend toward specialized AI hardware in consumer devices.
Personalization and adaptation
AI systems are becoming better at adapting to individual speakers, learning personal vocabulary, speaking patterns, and preferences over time while maintaining privacy.
Real-time language translation
Combining speech-to-text with language models enables real-time translation applications that could break down language barriers in global communication.
Speech language models
Speech language models that combine LLM reasoning with audio processing are emerging, enabling contextual understanding beyond simple transcription—making speech recognition systems that truly understand rather than just transcribe.
Getting started with speech-to-text AI
Speech-to-text AI has reached enterprise-grade reliability. The question isn't whether it can work for your application, but which approach fits your specific requirements.
Start by clearly defining your accuracy requirements, user experience goals, and technical constraints. Consider beginning with a pilot implementation using a robust API-based solution to validate your concept before committing to larger architectural decisions.
Speech-to-text AI has matured beyond basic transcription into a reliable foundation for voice-enabled products. Success depends on matching the right solution to your specific accuracy, latency, and integration requirements. Whether enhancing existing applications or building new voice interfaces, the technology now offers enterprise-grade reliability that transforms user interactions.
AssemblyAI's Speech AI models deliver enterprise-grade accuracy with comprehensive documentation and developer support. Start building with our API and get $50 in free credits to test integration.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts