How to choose the best speech-to-text API for voice agents
Choose the right speech-to-text API for voice agents. Learn the latency, accuracy, and integration requirements that actually matter for real conversations.




Companies building with voice represented 22% of the most recent Y Combinator class, and 39% of consumers are already comfortable with AI agents scheduling appointments for them.
But here's the challenge: standard speech-to-text benchmarks don't predict voice agent performance in real conversations. Generic accuracy scores and processing speeds don't predict how your API handles real conversations.
We'll walk through the voice agent-specific evaluation criteria that actually matter for building responsive, reliable voice experiences. For a comprehensive introduction to the technology, explore our complete guide to AI voice agents.
The voice agent speech-to-text core requirements
Voice agents have fundamentally different requirements than traditional transcription applications. Success depends on three non-negotiable technical foundations.
Latency rule: Demand sub-300ms response times
Humans respond within 200ms in natural conversation, so anything over 300ms feels robotic and breaks the conversational flow. This isn't just about processing speed—it's about end-to-end latency from speech input to actionable transcript.
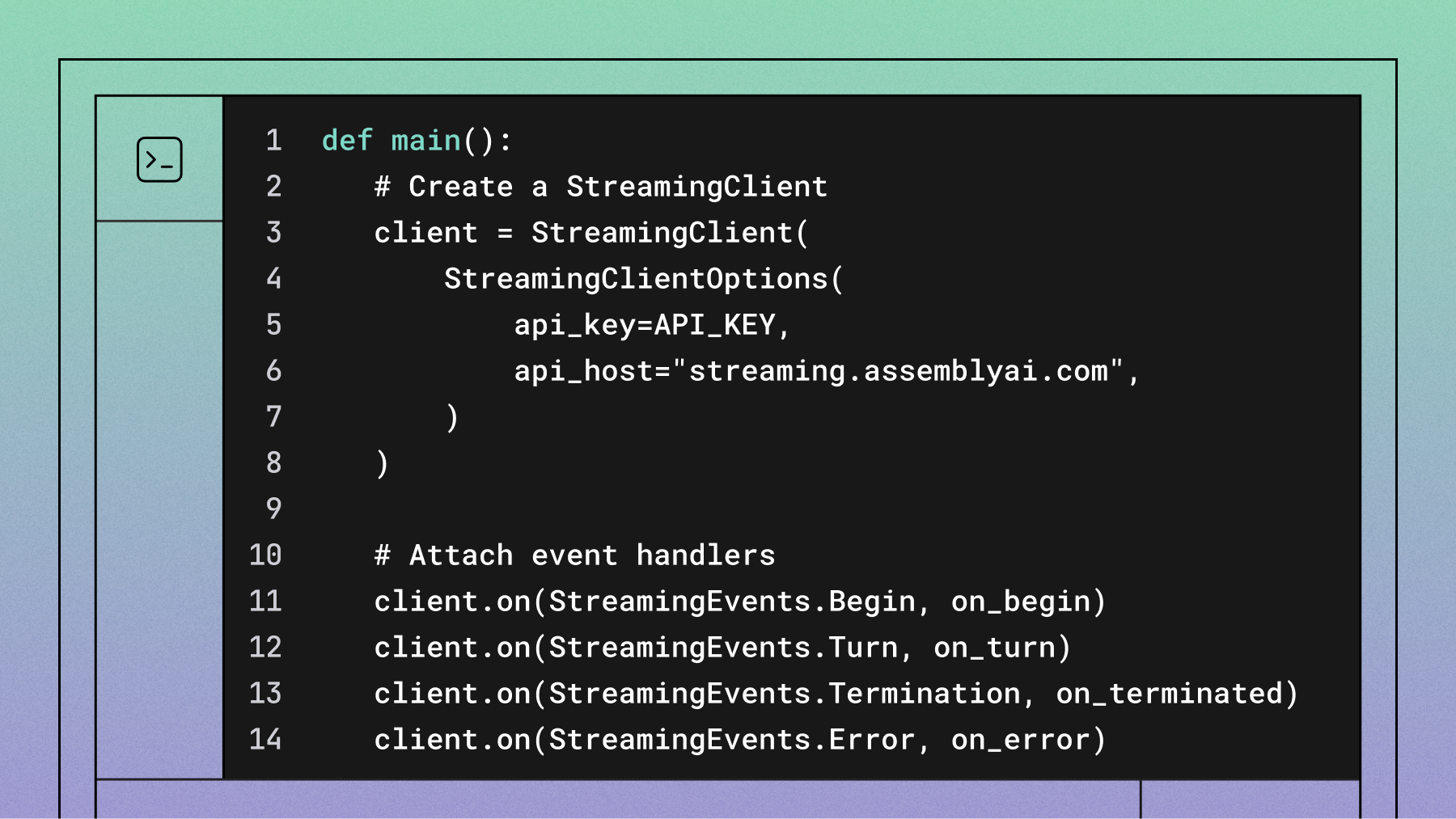
The red flag here is APIs that only quote "processing time" without addressing end-to-end latency. Look for immutable transcripts that don't require revision cycles. Here's what most developers don't realize: when your speech-to-text API 'revises' transcripts after delivery, your voice agent has to backtrack and say 'actually, let me rephrase that.' For example, Universal-Streaming's immutable transcripts in ~300ms eliminate these awkward moments entirely.
Critical token accuracy: Test with your actual business data
Generic word error rates tell you nothing about voice agent performance. What matters is accuracy on the specific information your voice agent needs to capture and act upon.
Test what actually matters to your business: email addresses, phone numbers, product IDs, customer names. When your voice agent mishears 'john.smith@company.com' as 'johnsmith@company.calm,' you've lost a customer.
Demand 95%+ accuracy on these business-critical tokens in your specific industry context. For example, Universal-Streaming shows 21% fewer alphanumeric errors on entities like order numbers and IDs compared to previous models—a significant improvement when every mistake costs customer confidence. See the detailed performance benchmarks for complete accuracy analysis.
Intelligent endpointing: Move beyond basic silence detection
Basic Voice Activity Detection treats every pause like a conversation ending. Picture this: someone says 'My email is... john.smith@company.com' with natural hesitation, and your agent interrupts with 'How can I help you?' before they finish. Semantic understanding fixes this.
Look for semantic understanding that distinguishes thinking pauses from conversation completion. The system should understand the difference between "I need to..." (incomplete thought) and "I need to schedule an appointment" (complete request).
Test this immediately with natural speech patterns. Have someone provide information with realistic hesitation, interruptions, and clarifications. If the system can't handle these common speech patterns, it won't work in production. Learn more about these common voice agent challenges and how modern solutions address them.
Integration considerations
Here's what most teams don't realize: technical implementation determines project success more than the underlying model quality. Three areas require careful evaluation.
Orchestration framework compatibility
Custom WebSocket implementations often cost 2-3x more in developer time than anticipated. The initial connection setup is straightforward, but handling connection drops, managing state, and implementing proper error recovery quickly becomes complex.
AssemblyAI provides pre-built integrations and step-by-step documentation for major orchestration frameworks like LiveKit Agents, Pipecat, and Vapi, reducing development time from weeks to days. This isn't just about convenience—it's about leveraging battle-tested code that handles edge cases your team hasn't encountered yet.
API design quality: Evaluate the developer experience
The quality of the developer experience directly impacts your implementation timeline and long-term maintenance costs. Green flags include comprehensive error handling, clear connection state management, and graceful degradation when network conditions change.
Red flags include poor documentation, limited SDK support, and unclear pricing for production loads. If basic setup takes more than 30 minutes, choose differently. The complexity only increases from there.
Can you establish a WebSocket connection, handle audio streaming, and process results with minimal code? The answer reveals whether you're dealing with a developer-focused API or an afterthought. For detailed technical guidance, review our streaming documentation.
Scaling considerations: Plan for success scenarios
Verify actual concurrent connection limits, not marketing claims. Some providers throttle connections aggressively once you exceed free tier limits, causing production failures during peak usage.
Geographic distribution matters for latency. Ensure low latency for your user base locations, not just major US markets. A voice agent with 150ms latency in San Francisco but 800ms in Singapore will fail international expansion.
Pricing transparency prevents those nasty budget surprises. Session-based pricing (like Universal-Streaming's $0.15/hour) offers predictable costs compared to complex per-minute models with hidden fees for premium features. For implementation best practices, check our guide to optimize your streaming implementation.
Business decision factors
Sure, technical capabilities matter. But vendor relationships? That's what determines long-term success. Three factors separate true partners from commodity providers.
Vendor commitment to voice AI
Evaluate recent product updates specifically for voice agents versus general transcription improvements. Universal-Streaming was purpose-built for voice agents, not adapted from general speech-to-text models. This focus shows in features like semantic endpointing and business-critical token accuracy.
Red flag: vendors treating voice agents as just another use case. If their recent releases focus on batch transcription or meeting notes rather than real-time conversation handling, they're not prioritizing your needs.
Total cost reality: Look beyond headline pricing
Integration development, ongoing maintenance, and feature add-ons create hidden costs that often exceed the base API pricing. Factor in reduced development time with better integrations when calculating ROI.
Scaling economics matter more than starter pricing. How does cost change with volume, enterprise features, and support requirements? A provider that's 20% cheaper initially but requires extensive custom development may cost 3x more over two years.
Risk management: Plan for vendor relationships
Financial stability enables long-term partnership. Can they support your growth and feature needs as you scale? Are they investing in voice agent capabilities you'll need in 12-18 months?
Compliance requirements vary by industry. SOC 2, HIPAA, and GDPR compliance aren't optional for many applications. Verify current certifications and compliance roadmaps.
Support quality becomes critical during production issues. Enterprise SLAs and technical support responsiveness can make the difference between a minor hiccup and a customer-facing outage.
Making your decision
Start with a focused proof of concept using your actual voice agent use case. Don't rely on generic demos or marketing materials. Test latency, accuracy, and integration complexity with your specific requirements.
Prioritize your evaluation criteria based on your actual use case. A customer service voice agent needs different capabilities than a voice-controlled IoT device. Focus your testing on the features that matter most for your application.
But here's the thing: implementation timeline constraints matter more than you think. If you need to launch in 8 weeks, choose the solution with the best existing integrations and support, even if another option might be technically superior with more development time. Our step-by-step voice agent tutorials can help you get started quickly.
Plan for monitoring and optimization post-deployment. Voice agent performance depends on continuous tuning based on real usage patterns. Choose a provider that offers analytics and optimization tools, not just basic transcription.
The voice agent market is moving fast, but the fundamentals remain consistent: low latency, high accuracy on business-critical information, and seamless integration. Focus your evaluation on these core requirements, and you'll build voice experiences that users trust and enjoy.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts