What is speaker diarization and how does it work? (Complete 2025 Guide)
In this blog post, we'll take a closer look at how speaker diarization works, why it's useful, some of its current limitations, and how to easily use it on audio/video files.




In this blog post, we'll take a closer look at how speaker diarization works, why it's useful, some of its current limitations, and how to easily use it on audio/video files.
What is speaker diarization?
In its simplest form, speaker diarization answers the question: who spoke when?
In the field of Automatic Speech Recognition (ASR), it refers to (A) the number of speakers that can be automatically detected in an audio file, and (B) the words that can be assigned to the correct speaker in that file. It can also be referred to as speaker segmentation or speech segments.
Speaker diarization performs two key functions:
- Speaker Detection: Identifying the number of distinct speakers in an audio file.
- Speaker Attribution: Assigning segments of speech to the correct speaker.
The result is a transcript where each segment of speech is tagged with a speaker label (e.g., "Speaker A," "Speaker B"), making it easy to distinguish between different voices.
How does speaker diarization work?
The fundamental task of speaker diarization is to apply speaker labels (i.e., "Speaker A," "Speaker B," etc.) to each word in the transcription text of an audio recording or video file.
Accurate diarization requires several steps that modern AI systems execute seamlessly:
- Step 1: Audio Segmentation
- Step 2: Speaker Embedding Generation
- Step 3: Speaker Count Estimation
- Step 4: Clustering and Assignment
Step 1: Audio segmentation
The first step breaks the audio file into a set of "utterances." What makes up an utterance? Generally, utterances are at least a half second to 10 seconds of speech. To illustrate this, let's look at the below examples:
Utterance 1: Hello my name is Cindy.
Utterance 2: I like dogs and live in San Francisco.
In the same way that a single word wouldn't be enough for a human to identify a speaker, machine learning models also need more data to identify speakers too. This is why the first step breaks the audio file into a set of "utterances" that can, later, be assigned to a specific speaker (e.g., "Speaker A" spoke "Utterance 1").
There are many ways to break up an audio/video file in a set of utterances, with one common way being to use silence and punctuation markers. In our research, we start seeing a drop off in the feature's ability to correctly assign an utterance to a speaker when utterances are less than one second.
Step 2: Speaker embedding generation
Once an audio file is broken into utterances, those utterances get sent through a deep learning model that has been trained to produce "embeddings" that are highly representative of a speaker's characteristics. An embedding is a deep learning model's high-dimensional representation of an input. For example, the image below shows what the embedding of a word looks like:
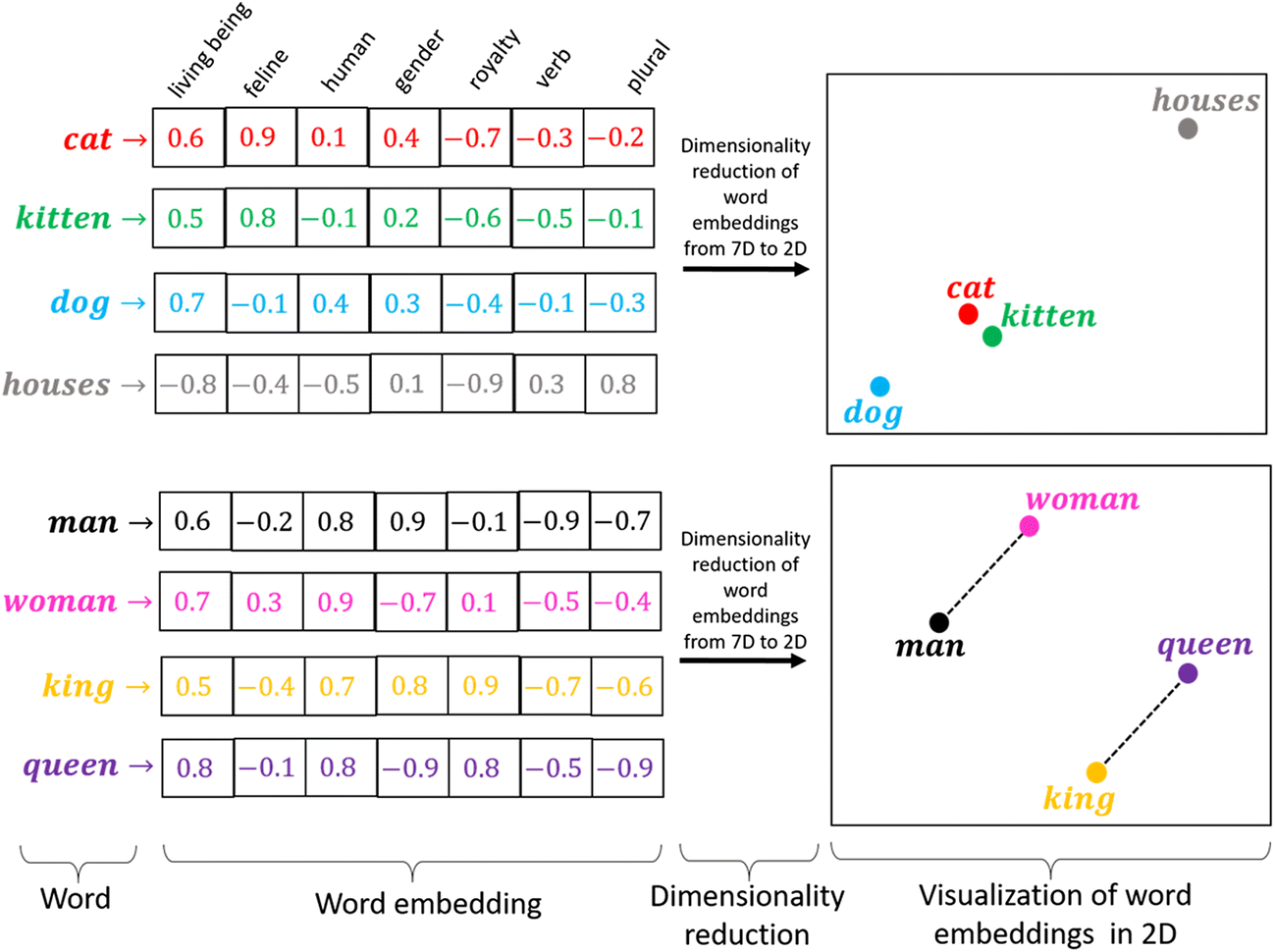
We do a similar process to convert not words, but segments of audio, into embeddings as well.
Step 3: Speaker count estimation
Next, we need to make a choice about how many speakers are present in the audio file—this is a key feature of a modern speaker diarization model. Legacy Diarization systems required knowing how many speakers were in an audio/video file ahead of time, but a major benefit of modern models is that they can accurately predict this number.
Our first goal here is to overestimate the number of speakers. Through clustering methods, we want to estimate the highest number of speakers that is reasonably possible. Why overestimate? It's much easier to combine speakers' utterances if the model breaks them up into different speaker labels than it is to disentangle two speakers being combined into one.
After this initial step, we go back and combine speakers, or disentangle speakers, as needed to get an accurate number.
Step 4: Clustering and assignment
Finally, speaker diarization models take the embeddings (produced above), and cluster them into as many clusters as there are speakers. For example, if a diarization model predicts there are four speakers in an audio file, the embeddings will be forced into four groups based on the "similarity" of the embeddings.
For example, in the below image, let's assume each dot is an utterance. The utterances get clustered together based on their similarity—with the idea being that each cluster is a unique speaker.
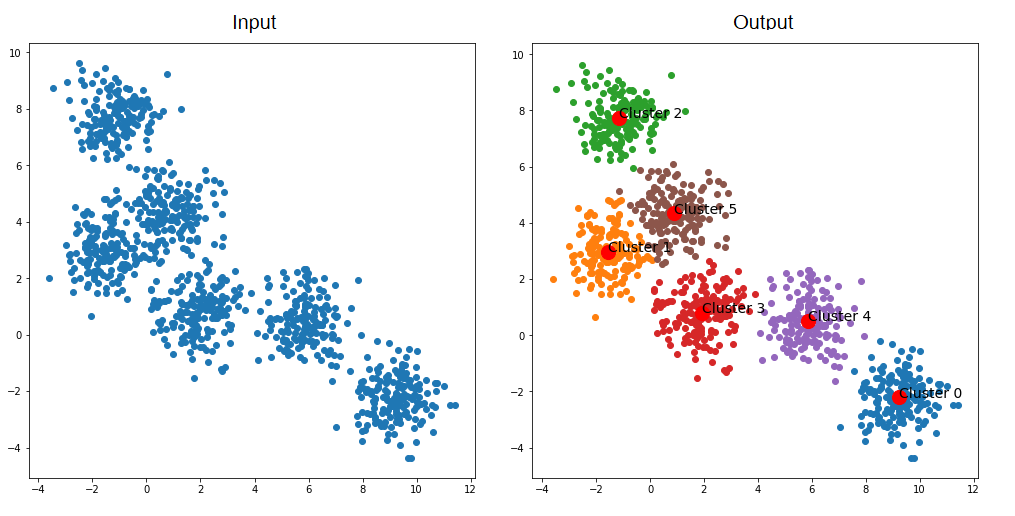
There are many ways to determine similarity of embeddings, and this is a core component of accurately predicting speaker labels with a Speaker Diarization model. Recent advances in speaker embedding models have improved clustering accuracy, particularly for short utterances and challenging acoustic conditions.
After this step, you now have a transcription complete with accurate speaker labels!
Today's models can be used to determine up to 26 speakers in the same audio/video file with high accuracy.
Why is speaker diarization useful?
Speaker diarization is useful because it takes a big wall of text and breaks it into something much more meaningful and valuable. If you were to try and read a transcription without speaker labels, your brain would automatically try and assign each word/sentence to the appropriate speaker. It also saves you time and mental energy.
For example, let's look at the before and after transcripts below with and without speaker diarization:
Without:
But how did you guys first meet and how do you guys know each other? I actually met her not too long ago. I met her, I think last year in December, during pre season, we were both practicing at Carson a lot. And then we kind of met through other players. And then I saw her a few her last few torments this year, and we would just practice together sometimes, and she's really, really nice. I obviously already knew who she was because she was so good. Right. So. And I looked up to and I met her. I already knew who she was, but that was cool for me. And then I watch her play her last few events, and then I'm actually doing an exhibition for her charity next month. I think super cool. Yeah. I'm excited to be a part of that. Yeah. Well, we'll definitely highly promote that. Vania and I are both together on the Diversity and Inclusion committee for the USDA, so I'm sure she'll tell me all about that. And we're really excited to have you as a part of that tournament. So thank you so much. And you have had an exciting year so far. My goodness. Within your first WTI 1000 doubles tournament, the Italian Open.Congrats to that. That's huge. Thank you.
With:
Speaker A: But how did you guys first meet and how do you guys know each other?
Speaker B: I actually met her not too long ago. I met her, I think last year in December, during pre season, we were both practicing at Carson a lot. And then we kind of met through other players. And then I saw her a few her last few torments this year, and we would just practice together sometimes, and she's really, really nice. I obviously already knew who she was because she was so good.
Speaker A: Right. So.
Speaker B: And I looked up to and I met her. I already knew who she was, but that was cool for me. And then I watch her play her last few events, and then I'm actually doing an exhibition for her charity next month.
Speaker A: I think super cool.
Speaker B: Yeah. I'm excited to be a part of that.
Speaker A: Yeah. Well, we'll definitely highly promote that. Vania and I are both together on the Diversity and Inclusion committee for the USDA. So I'm sure she'll tell me all about that. And we're really excited to have you as a part of that tournament. So thank you so much. And you have had an exciting year so far. My goodness. Within your first WTI 1000 doubles tournament, the Italian Open. Congrats to that. That's huge.
Speaker B: Thank you.
See how much easier the transcription is to read with speaker diarization?
It is also a powerful analytic tool. When you identify and label speakers, you can analyze each speaker's behaviors, identify patterns/trends among individual speakers, make predictions, and more. For example:
- A call center might analyze agent messages versus customer requests, or complaints, to identify trends that could help facilitate better communication.
- A podcast service might use speaker labels to identify the <host> and <guest>, making transcriptions more readable for end users.
- A telemedicine platform might identify <doctor> and <patient> to create an accurate transcript, attach a readable transcript to patient files, or input the transcript into an EHR system.
Industry applications
These applications are already delivering measurable results for organizations across industries. For example, hiring intelligence platform Screenloop uses AI-powered transcription and speaker diarization to help its customers realize a 90% reduction in time spent on manual hiring and interview tasks, 20% reduced time to hire, and improved training effectiveness while reducing hiring bias.
Limitations and challenges of speaker diarization
Currently, Speaker Diarization models only work for asynchronous transcription and not real-time transcription, however this is an active area of research.
There are also several constraints that limit the accuracy of modern models:
- Speaker talk time
- Conversational pace
A speaker's talk time has the biggest impact on accuracy. If a speaker talks for less than 15 seconds in an entire audio file, it's a toss-up as to if a model will correctly identify this speaker as a unique, individual speaker. If it cannot, two outcomes may occur: the model may assign the speaker as <unknown>, or it may merge their words with a more dominant speaker. Generally speaking, a speaker has to talk for more than 30 seconds in order to accurately be detected by a model.
Audio files with a conversational pace have the second biggest impact on accuracy. If the conversation is well-defined, with each speaker taking clear turns (think of a podcast interview versus a phone call conversation), has an absence of over-talking or interrupting, and minimal background noise, it is much more likely that the model will correctly label each speaker. However, if the conversation is more energetic, with the speakers cutting each other off or speaking over one another, or has significant background noise, the model's accuracy will decrease. If overtalk (aka crosstalk) is common, the model may even misidentify an imaginary third speaker, which includes the portions of overtalk.
Different providers have varying speaker limits—AssemblyAI supports up to 10 speakers by default, with configuration options for specific use cases.
Recent improvements have reduced errors when speakers have similar voices.
While there are clearly some limitations to speaker diarization today, Speech-to-Text APIs like AssemblyAI are using deep learning research to overcome these deficiencies and boost speaker diarization accuracy.
Using speaker diarization technology
While the models behind speaker diarization technology may seem complex, using diarization on audio files is thankfully quite simple.
AssemblyAI offers accurate transcription and speaker diarization, with recent significant model improvements that realize 30% better diarization in noisy audio and overlapping conditions..
All you have to do is run your audio file through the AssemblyAI API to get an accurate transcription, with speaker labels assigned to each word in the transcription file. The API will identify a label per word that shows which speaker spoke when.
To get started, enable speaker_labels=true in your API call to access these capabilities at no additional cost.
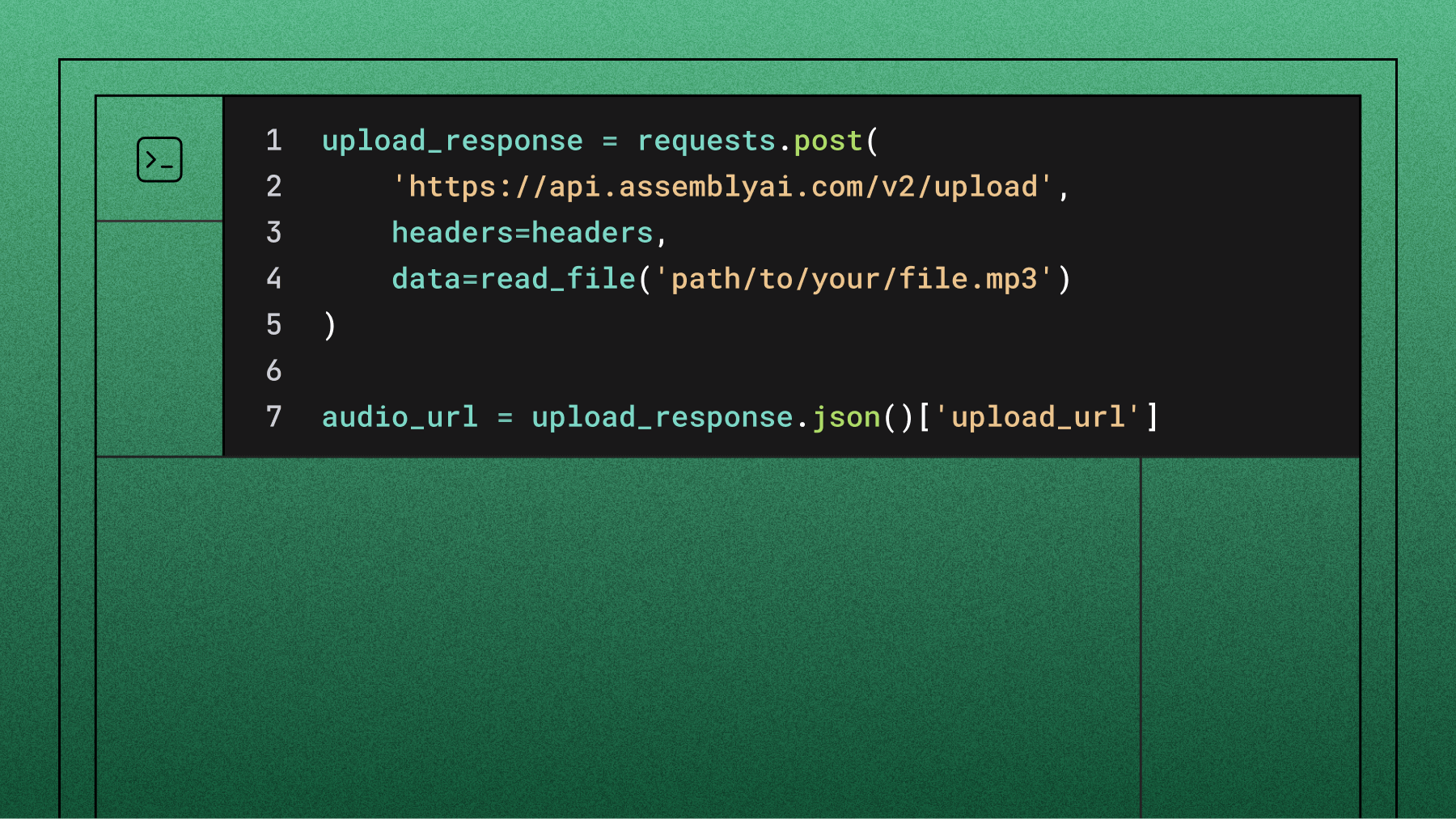
import requests
import time
base_url = "https://api.assemblyai.com"
headers = {
"authorization": "<YOUR_API_KEY>"
}
with open("./my-audio.mp3", "rb") as f:
response = requests.post(base_url + "/v2/upload",
headers=headers,
data=f)
upload_url = response.json()["upload_url"]
data = {
"audio_url": upload_url, # You can also use a URL to an audio
or video file on the web
"speaker_labels": True
}
url = base_url + "/v2/transcript"
response = requests.post(url, json=data, headers=headers)
transcript_id = response.json()['id']
polling_endpoint = base_url + "/v2/transcript/" + transcript_id
while True:
transcription_result = requests.get(polling_endpoint,
headers=headers).json()
if transcription_result['status'] == 'completed':
print(f"Transcript ID:", transcript_id)
break
elif transcription_result['status'] == 'error':
raise RuntimeError(f"Transcription failed:
{transcription_result['error']}")
else:
time.sleep(3)
for utterance in transcription_result['utterances']:
print(f"Speaker {utterance['speaker']}: {utterance['text']}")
For a complete implementation guide, see our Python speaker diarization tutorial.
AssemblyAI's new speaker diarization model delivers significant improvements in real-world audio conditions:
- 20.4% error rate in noisy, far-field scenarios (down from 29.1%) - a 30% improvement for challenging acoustic environments where traditional systems fail
- Accurate speaker identification for 250ms segments - enabling tracking of single words and brief acknowledgments
- 57% improvement in mid-length reverberant audio - better performance in conference rooms and large spaces
- Automatic deployment - All customers benefit immediately with no code changes required
These improvements specifically target the challenging scenarios that break existing systems: conference room recordings with ambient noise, multi-speaker discussions with overlapping voices, and remote meetings with poor audio quality. Learn more about implementation options.
Frequently Asked Questions
Q: What's the difference between speaker diarization and speaker recognition? Speaker diarization identifies different speakers without knowing who they are ("Speaker A" vs "Speaker B"), while speaker recognition identifies specific individuals by matching their voice to a known database.
Q: How many speakers can speaker diarization detect? Modern systems can detect anywhere from 2 to 30+ speakers depending on the provider and configuration. For example, AssemblyAI supports up to 10 speakers by default.
Q: Which languages support speaker diarization? Language support varies by provider. English is universally supported, with many systems now offering multilingual capabilities. AssemblyAI, for instance, supports 16 languages including Spanish, French, German, and others.
Q: Can speaker diarization work in real-time? Most production systems currently process recordings asynchronously for optimal accuracy. Real-time diarization is an emerging capability with some providers offering it for specific use cases.
Q: How accurate is speaker diarization? Diarization Error Rate (DER) varies significantly by provider and conditions. AssemblyAI achieves a 2.9% speaker count error rate, which measures accuracy in determining the correct number of speakers, with recent advances showing significant improvements in challenging audio environments including accurate speaker identification for segments as short as 250ms.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts